Production AI Agents: 3 Control Systems That Actually Hold Up

Most AI agents survive the demo and collapse in production. The runaway session that silently burns API credits for hours. The tool call that mutates a filesystem while another reads it. The context window that overflows three hours into a customer workflow. These aren't model failures, they're harness failures.
At DataGOL, months of iteration on our agentic layer surfaced one consistent pattern: reliable production agents require three distinct control systems — execution, context, and trust. This is a field report on what we built, what broke, and which design choices held up when agents moved from demos to long-running customer workflows for SaaS companies shipping AI features in days rather than months.
Our agents perform large data analysis, code generation and execution, dashboard creation, document extraction, and bespoke customer workflows as part of AgentOS. After months of iteration, we found that the recurring issues weren't due to the model's inability to generate possible next steps, but rather because the agent loop ran too long, produced excessive output, failed in ways that were difficult to recover from, and ultimately couldn't deliver useful results once a task started to drift.
The harness did not emerge as a neat stack of subsystems. Most of the lessons came from three recurring themes: controlling execution, controlling context, and controlling trust. We started with well-documented harness engineering principles informed by work on Anthropic's agent design research and the Model Context Protocol specification and kept building from what we discovered during failing runs, where tool use, permissions, memory, and recovery problems tended to compound rather than appear one at a time.
💸 What $12 taught us about production agent costs
Early on, a runaway session quietly burned through about $12 of API usage before anyone intervened. The model was not doing anything malicious. It was simply stuck in a loop we had not bounded well enough, carrying too much context, making too many calls, and failing in a way that looked superficially productive until we inspected the trace.
$12 is a rounding error. But at scale hundreds of agent sessions running customer workflows in parallel unbounded loops are how production agent deployments die. That single incident captured the real problem better than any architecture diagram could: once agents are attached to tools, data, and code execution, the hard part is no longer text generation. The hard part is controlling what happens around it.
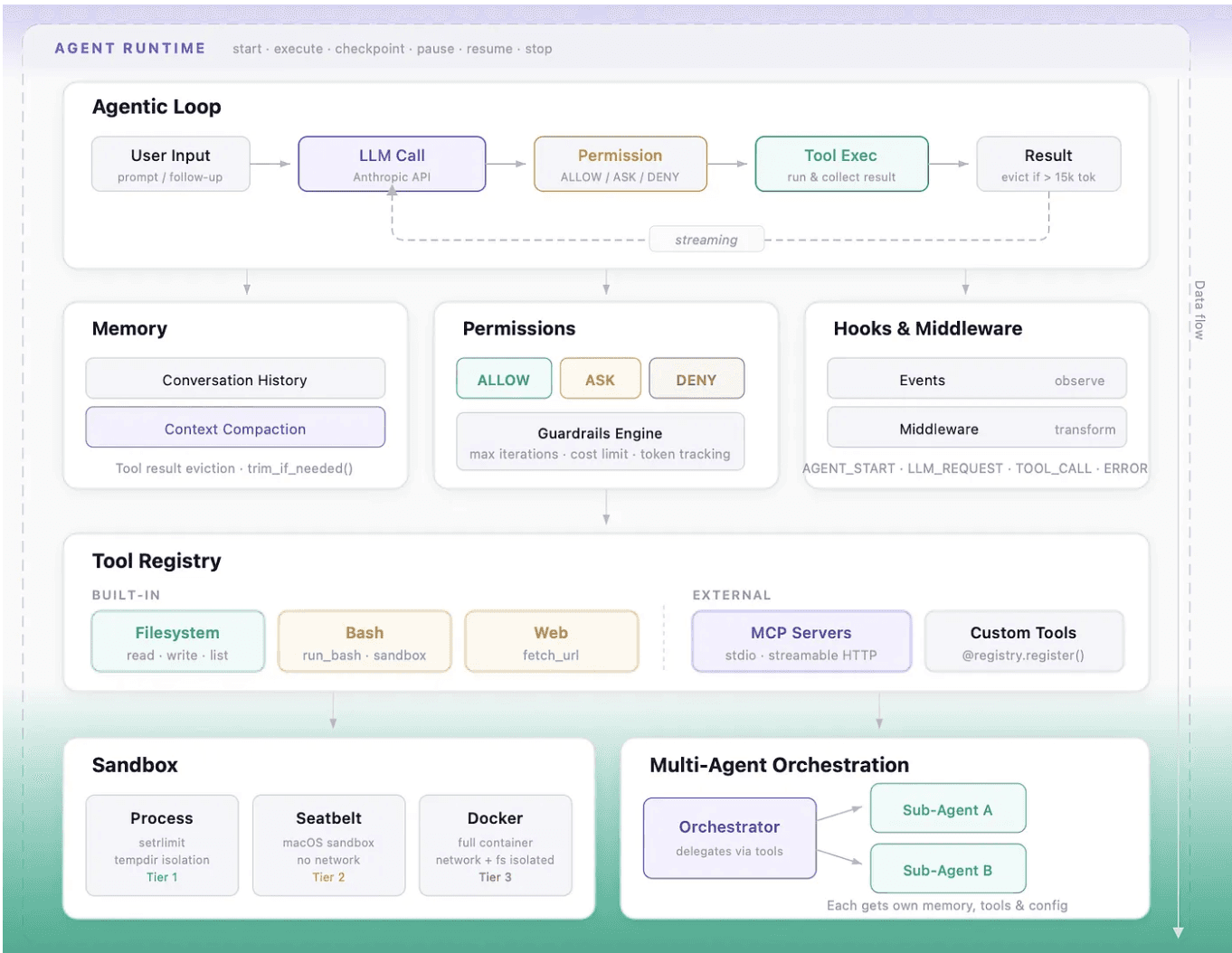
Part I - Controlling Execution
Why do AI agents run away in production, and how do you prevent it?
Production AI agents run away because the harness around them lacks bounded retries, enforced tool sequencing, and clear recovery paths. Our earliest failures were not caused by the model being unable to reason. They came from the system executing actions without enough control around retries, tool use, and recovery. That is why the core loop, the tool registry, the runtime, and sub-agent delegation are all part of the execution control plane. They are just different knobs to keep the agent on track much like the controls on a game controller that keep a player on course.
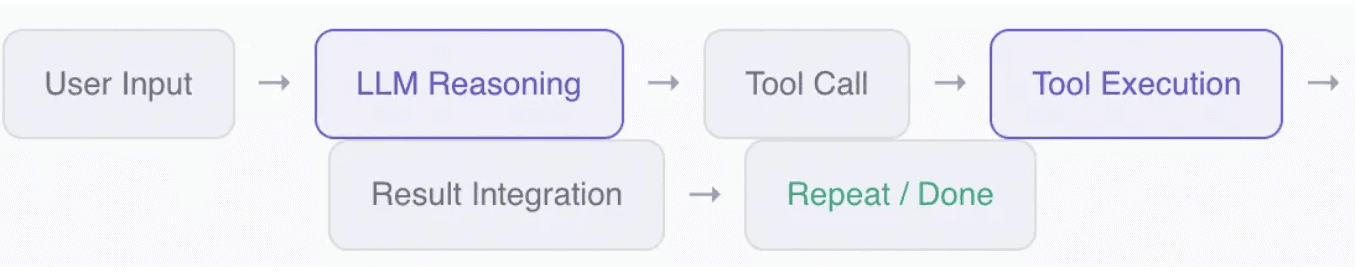
When does a basic agent loop stop being sufficient?
The basic loop is not the interesting part. Every agent framework has some version of it. What mattered was noticing when a simple loop stopped being useful and started causing real problems: repeated retries, oversized outputs, and multiple actions proposed in a single turn with no clear sequencing.
The LLM never runs the tools —
it emits a structured request, and the harness does the actual execution. That sounds simple until, for example, the model emits multiple tool calls in one response, one tool mutates the filesystem while another reads it, and the trace stops being easy to reason about. The important lesson was that the harness needs full control to slow the agent down with checks, limits, or explicit sequencing.
Why is tool design itself a form of execution control?
The tool registry mattered less as a developer convenience and more as the place where execution rules became enforceable. Yes, it auto-generates JSON Schema for tool calling from Python type hints and "docstrings". But more importantly, registration, permission, and failure behaviour can all be controlled from the same plane. That is where we stopped treating "any callable" as a tool candidate and started deciding whether a tool could fail clearly, accept bounded input, and expose side effects the model could reason about.
How you design your tools is as important as how you design the harness.


That pattern is simple but powerful. A bad tool call does not get to crash the harness. A missing tool becomes a structured error. A handler traceback becomes something the agent can see and potentially recover from on the next turn. We also became much stricter about what deserved registration. If a callable had ambiguous side effects, unbounded inputs, or error surfaces the model could not act on, that was a tool-design failure, not a runtime failure.
MCP followed the same pattern: remote tools were only manageable once they were registered into that same control plane.
![Diagram showing MCP remote tools registered into the same DataGOL tool registry as local tools, with uniform permission and error handling]](https://framerusercontent.com/images/FO7wiNj48raXUdIi0766XM4yiEw.png)
How do long-running AI agents survive interruption?
Long-running sessions needed more than the core loop, but the current runtime is intentionally modest. In this codebase, AgentRuntime wraps the base agent with session directories, checkpointing, pause and resume, cleanup, and status reporting. This matters because a long-running agent eventually needs to survive interruption, not just complete a happy-path run.

![Python code showing the AgentRuntime wrapper around the base agent, with explicit hooks for checkpoint, resume, and cleanup]](https://framerusercontent.com/images/2mFQV6ao1I5OIkWf79jwogPhUM.png)
Part II — Controlling Context
How do you manage context for long-running AI agents?
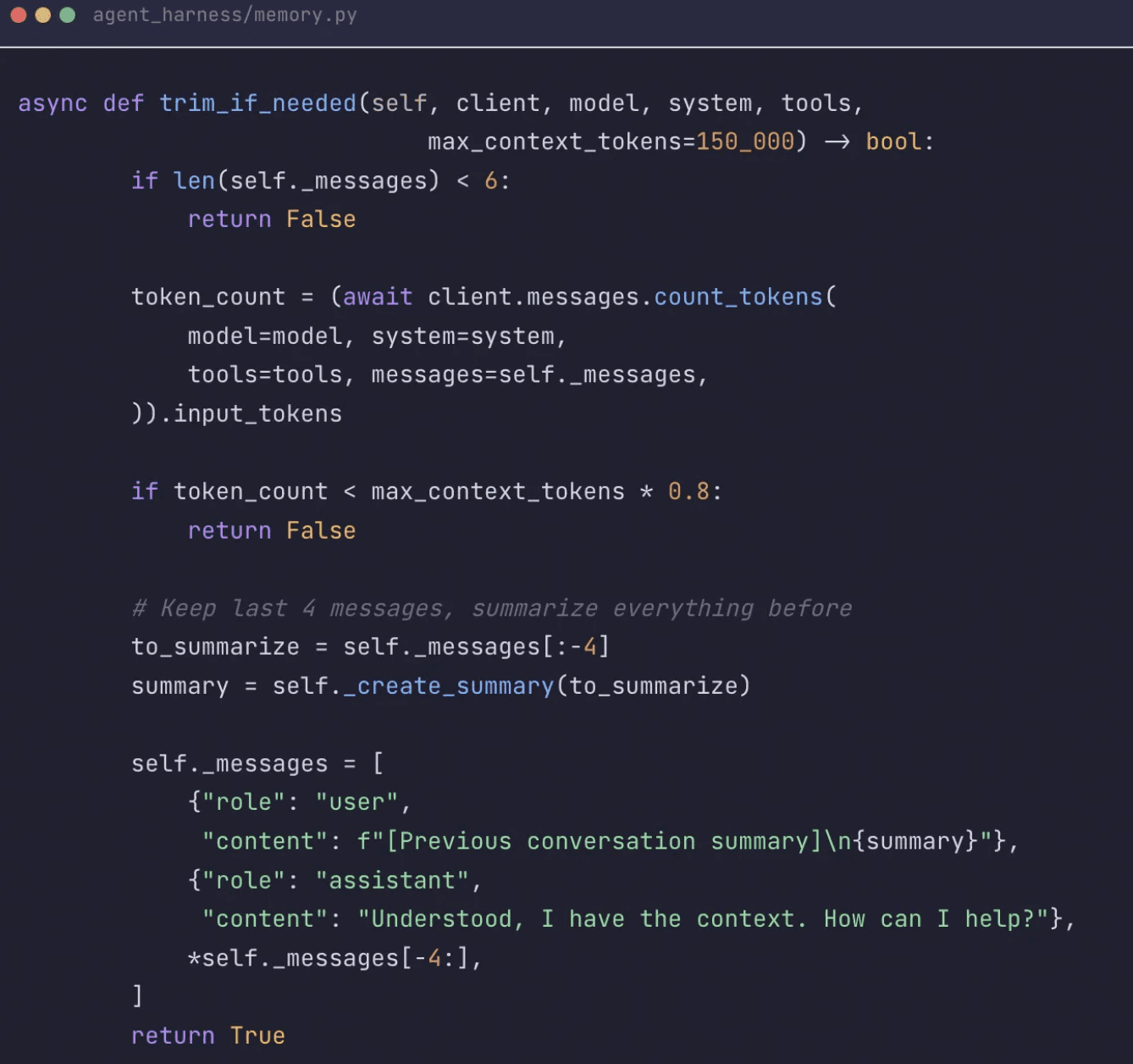
You manage context for long-running AI agents by actively deciding what stays in the live prompt, what gets evicted to disk with a retrieval handle, and what is compacted into summary form. It's hard to go a day without hearing about "context engineering." At its core, it's an all-inclusive idea of how to provide the right amount and type of information to the agent at the right time. Once again, it's the harness's responsibility to make that happen to the best of its ability. The harness decides what must stay in the active context, what needs to be moved out from a large tool call output, and how the agent can retrieve it later if needed.
Why can't you just keep tool outputs in the prompt?
A single successful tool call that returns far more than the next model invocation needs is a pressure point for the agent. A full SQL dump, a verbose schema inspection, or a giant traceback can silently bloat the conversation until the next call fails with a token error. That is what led us to build large-result eviction directly into the loop.
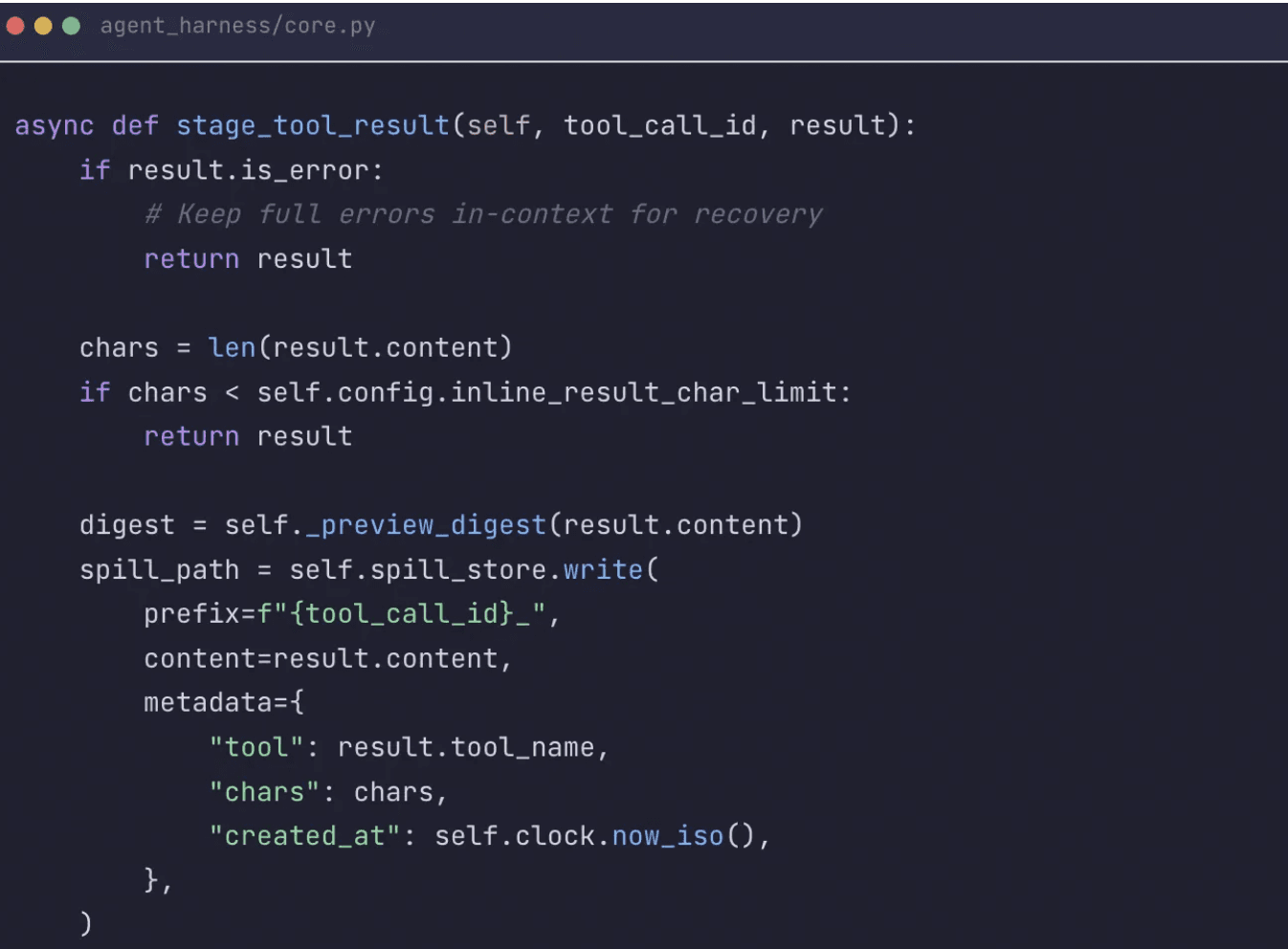
Our solution was not generic truncation but a spill-to-disk policy. Large successful outputs are staged outside the live context and replaced with a compact digest plus a precise recovery path back to the raw artifact. One exception: errors do not get offloaded. When a step fails, a full stack trace gives the agent a fair opportunity to recover without omitting important details.
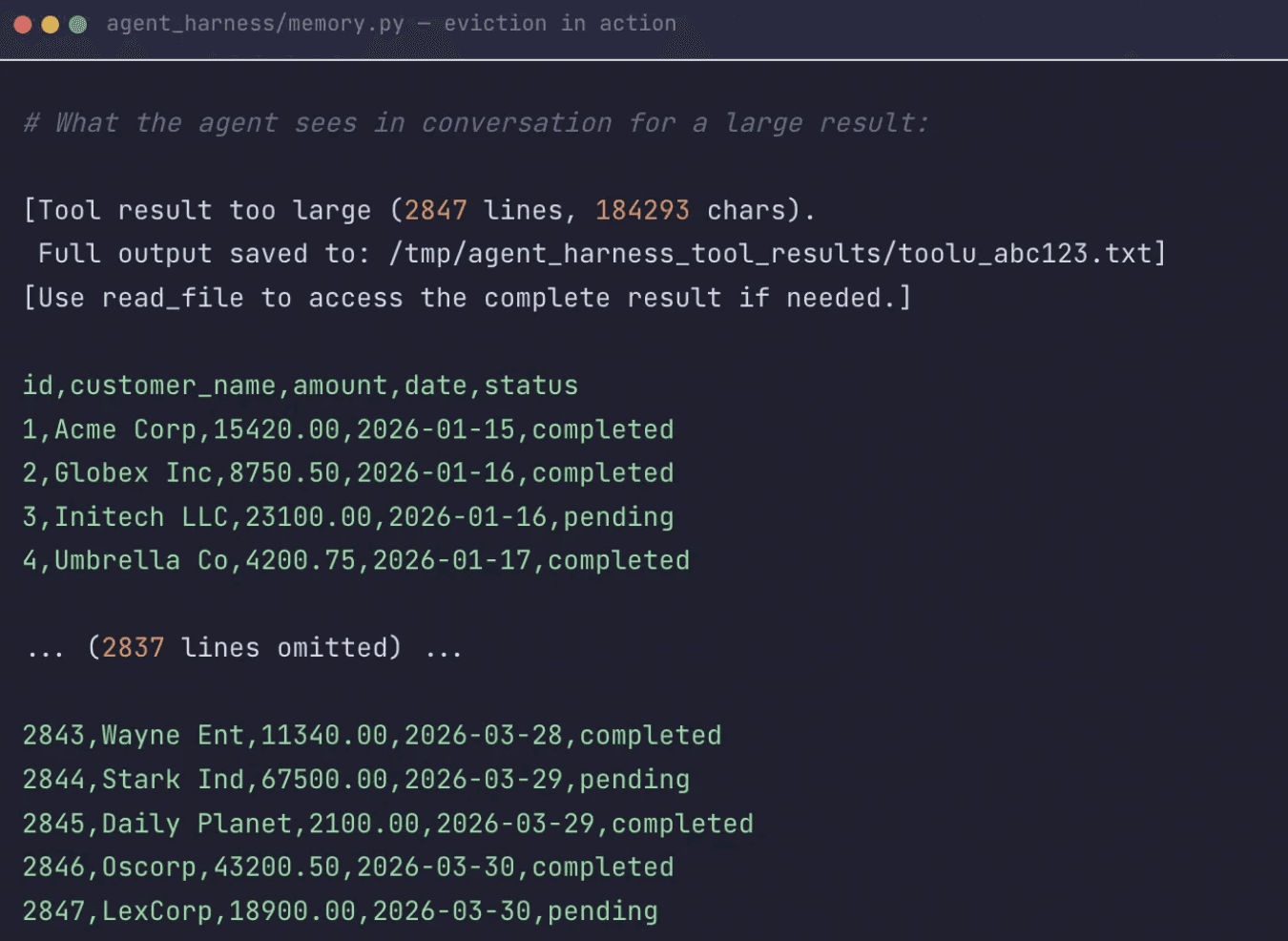
How do you keep the context window from overflowing on long sessions?
Once large tool results were being evicted correctly, the next problem was cumulative growth. Context compaction — summarizing older conversation history while keeping recent turns intact — is a practical way to keep the context window from overflowing while maintaining conversational continuity. It is lossy, and we have accepted that for now. The tradeoff is worth it: a session that compacts gracefully and keeps running for eight hours is more valuable than a session that preserves every token for ninety minutes and then fails.
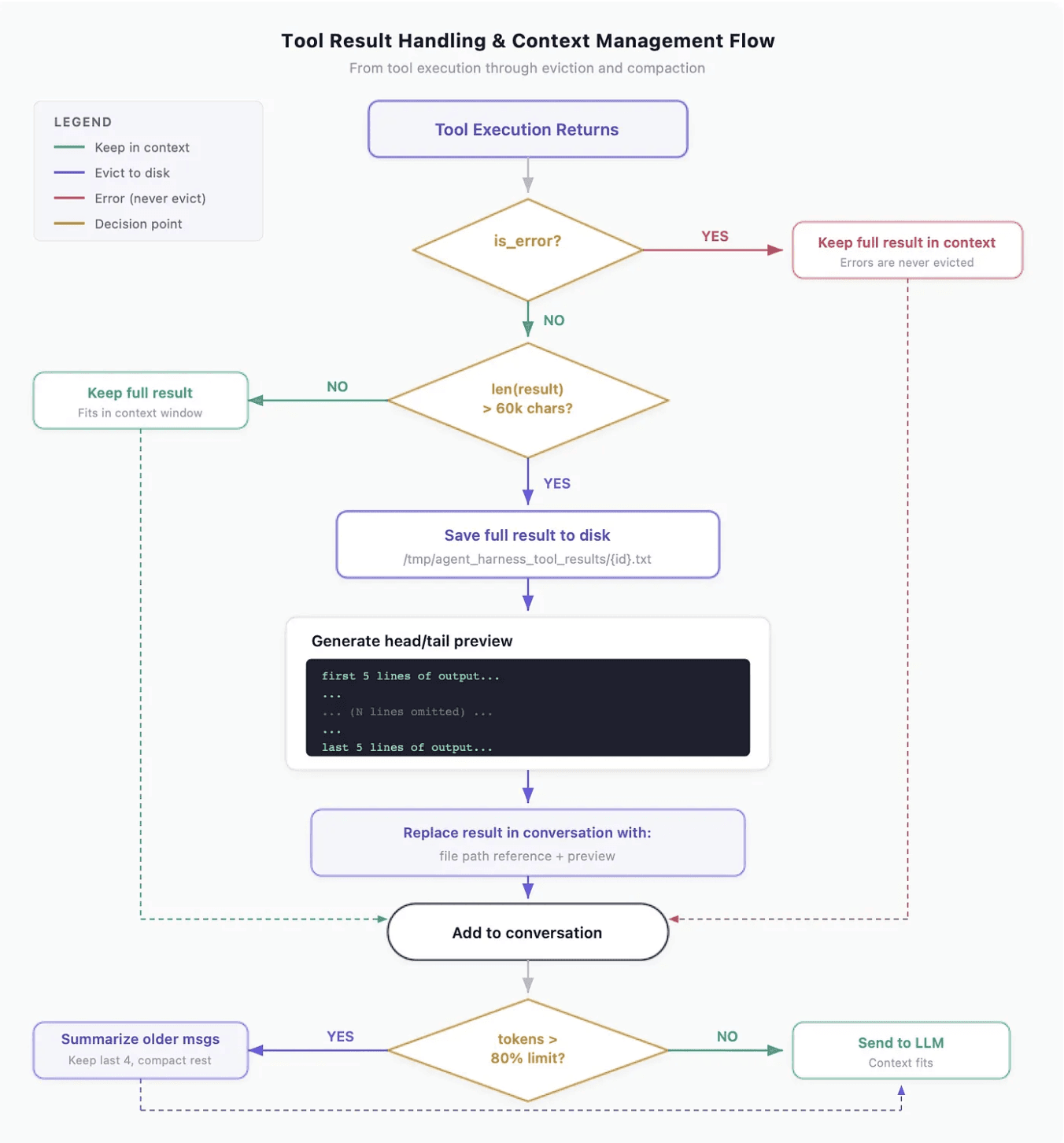
Why did we split agent memory into four separate stores?
One shared memory store kept surfacing the wrong information. Conversation history bled into long-term facts, user preferences got retrieved when we needed agent-authored notes, and everything competed for the same slot in the prompt. We split memory into four stores because the four categories serve genuinely different retrieval patterns:
Conversation memory — stays in the provider's native message format. No translation layer, no extra debugging overhead.
Long-term memory — facts and learned information that persist across sessions, stored in a database.
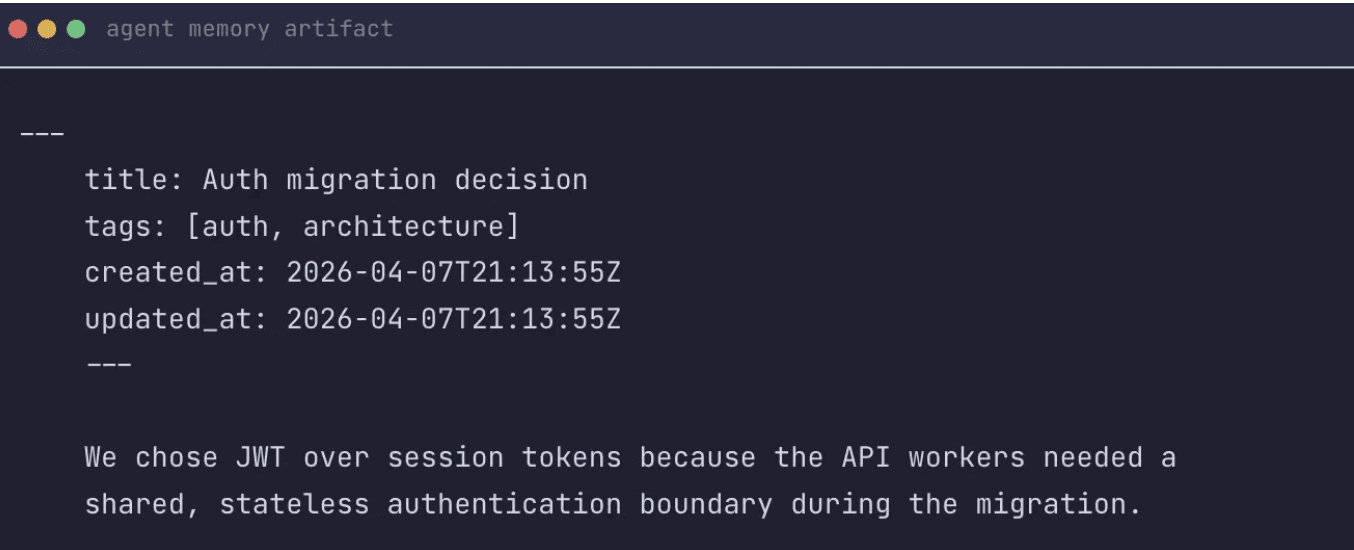
Agent-authored notes — markdown files with frontmatter. Reviewable and editable by humans, searchable by tags.
Preference memory — durable user corrections and working-style patterns, stored in a vector database for semantic retrieval.
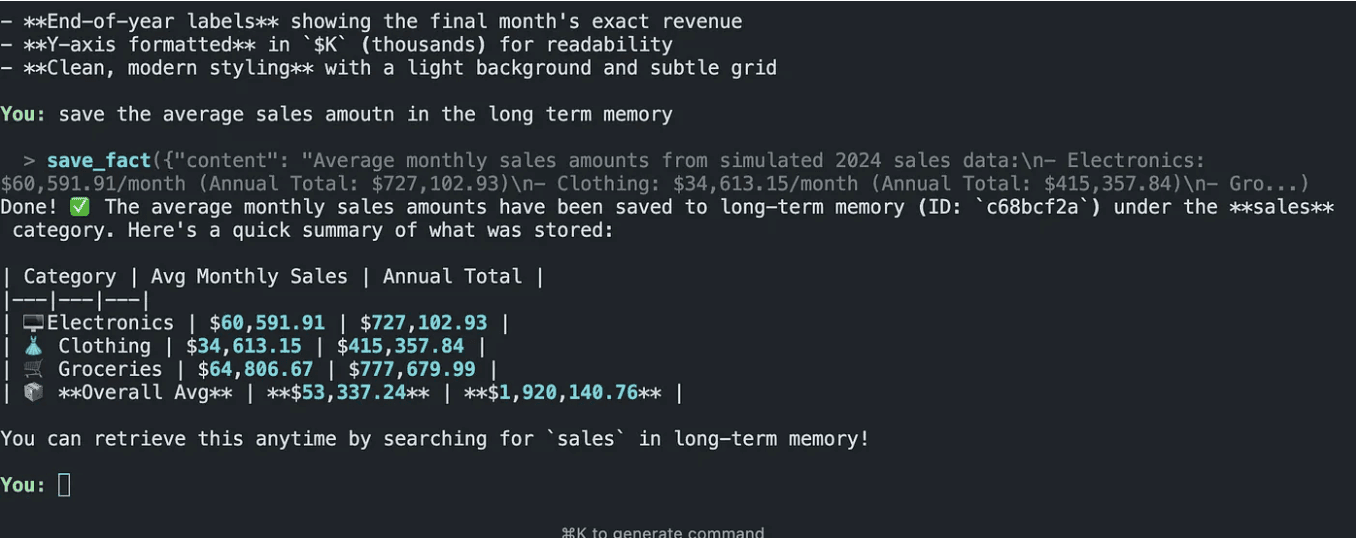
A concrete memory write in the CLI: the agent stores a summarized sales fact in longterm memory and returns the saved record details.
Part III — Controlling Trust
How do you give AI agents tool access safely?
You give AI agents tool access safely by treating every tool as having an explicit permission level, enforcing those permissions before execution, isolating side-effecting work in a sandbox, and making every decision observable in real time. Once the agent can read and write files, run commands, resume sessions, and touch outside systems, the harness's responsibility extends far beyond steering the agent to produce results. It becomes imperative that a human can understand what the agent is doing, stop it when necessary, and expect failures to surface as clear errors rather than surprising side effects.
Why are explicit permissions a first-class concept, not an afterthought?
Every tool has a permission level: ALLOW, ASK, or DENY. When a tool is set to ASK, the harness shows the tool name and input and waits for confirmation. We intentionally avoided trying to auto-classify whether a command was "probably safe," because several individually harmless actions can still become risky once they are chained together.
![Diagram showing the three permission states with example tool assignments — read_file as ALLOW, write_file as ASK, shell_exec as ASK, delete_resource as DENY by default]](https://framerusercontent.com/images/DA9qL17RDHmGoGe8zlS4t90EGY.png)
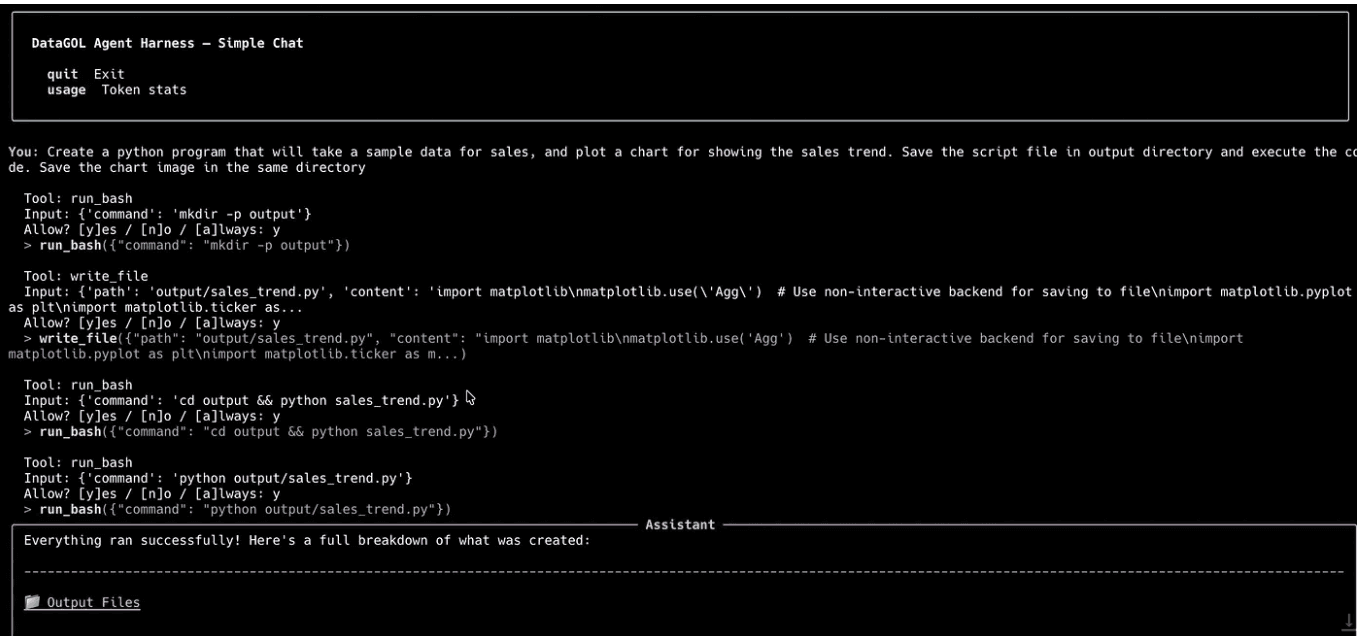
The permission flow in practice: each potentially risky tool call is surfaced with its input before execution, making approvals inspectable instead of implicit.
The same philosophy shows up in the guardrails layer. GuardrailsEngine enforces boundaries, while PermissionManager decides whether a tool call is allowed to proceed at all. That combination mattered more than any single safety abstraction because it addressed both classes of failure we saw: sessions that ran too long and actions that were locally risky even inside a healthy run.

How do you sandbox AI agents that execute real code?
Our agents run real commands against real systems. When an agent can access file systems and execute bash or Python scripts, a misguided file operation like "rm -rf" would ruin someone's week. The sandbox creates a scoped, temporary work directory, runs code or shell commands inside that directory, applies timeout and resource limits, and reports back which files were touched.

Just as importantly, the sandbox remains independent from the tool system. The bash tool can use it, but the sandbox itself only knows how to isolate and execute work, which keeps the contract narrow and replaceable. Independence is a feature: it means we can swap sandbox implementations (local process isolation, containers, microVMs) without touching tool code.
What observability does a production AI agent need?
Users needed to understand what the agent was doing while it ran, not just what it had done after completion. We use hooks for observability: they log checkpoints, record sandbox executions, and emit audit events without being allowed to modify the run. Middleware is the intervention layer — where we deliberately allow the pipeline to reshape messages, tools, tool calls, or tool results.
Events flow through the system: AGENT_START , LLM_REQUEST , TOOL_CALL_START , TOOL_CALL_END , LLM_RESPONSE , ERROR . Each point in the lifecycle is observable and interceptable.

What We Actually Learned About Production AI Agents
Over time, the harness stopped feeling like a list of components and started feeling like three recurring engineering problems that need regular evaluation. We kept having to control execution, context, and trust.
The second point worth mentioning: most learnings came from failures rather than architectural foresight. The building blocks emerged when agents were failing in unexpected ways and we spent days fixing them. This is why DataGOL customers can ship AI features into their SaaS products in 8–10 weeks rather than 9+ months — not because the model got smarter, but because the harness absorbed years of failure modes that every team would otherwise have to rediscover from scratch.
If we were to rebuild from scratch, we would still optimize for control before convenience. We would start with bounded execution, recoverable tool errors, explicit permissions, controlled context, and inspectable runtime state. The harness is not decoration around the agent. It is the part that makes the agent operational in a safe and consistent manner.
Ship AI features into your SaaS product in days, not months.
DataGOL provides the agent harness, semantic layer (ContextOS), and multi-agent orchestration (AgentOS) as a single platform — so your team doesn't have to rebuild control systems from scratch.
→ Schedule a 2-Week Proof of Value to see your own data running on DataGOL with AI features deployed end-to-end.


Author
Jyotish Bora
Jyotish Bora is a visionary technology strategist with over 18 years of experience driving digital transformation across global organizations. Based in Chicago, Jyotish serves as VP of Engineering at DataGOL, following strategic roles at Lab49 and InComm Payments. He specializes in crafting forward-thinking AI adoption strategies and architectural roadmaps that guide companies through technological evolution. He holds a Master of Science in Computer Science from Clemson University and a Bachelor of Science from the National Institute of Technology, Bhopal, India.


