How to Ship AI Features Faster | DataGOL

Stop Rebuilding the Foundation for Every AI Feature
According to KPMG's 2026 AI Pulse Survey, 65% of engineering leaders cite agentic system complexity as their top barrier - not model quality, not AI talent. Deloitte puts it more bluntly: only 11-14% of enterprise AI agent pilots reach production at scale, with the failures attributed primarily to data fragmentation, integration complexity, and governance gaps. They stall because five distinct infrastructure layers need to be assembled before the model can do anything useful in production: connected business data, reusable context, governed tool access, orchestration, and an agent harness that holds under real workloads.
Each of those layers is a separate ticket, a separate team, and a separate sign-off cycle. That's the actual bottleneck.
The bottleneck is stack assembly. Fragmented data pipelines, missing context layers, weak governance, and brittle orchestration glue add up to weeks of cross-team coordination before a single production-grade AI feature ships.
This post breaks down exactly where that time goes, and why collapsing those layers into one governed system is the fastest path to production.
The Five Layers Teams End Up Rebuilding for Every Feature
Google's 2026 AI trends report notes the market is moving from one-off prompts to action-oriented agents embedded in workflows. IBM puts it plainly: effective agents can accelerate business processes by 30-50%. But neither of those outcomes is reachable until the underlying system is production-ready. That means assembling five distinct layers, usually across four different teams:
Data connectivity: Pulling live, clean, business-relevant data from Salesforce, Stripe, NetSuite, HubSpot, and wherever else it lives. Not a one-time job. Every new feature needs a new slice of it.
Trusted context: Structuring that data so the model can reason over it accurately. Raw data is not AI-ready data.
Governed tool access: Wiring up the tools the agent calls, with permission controls that security and compliance will actually approve.
Orchestration glue: Coordinating multi-step agent workflows without building a custom state machine from scratch.
Agent harness: Evaluation, observability, memory, and retry logic. The scaffolding that keeps production agents from going off-rail.
Each layer is a legitimate engineering problem. The issue is that teams rebuild all five from scratch for every feature, burning roadmap time before any model-specific work begins.
The Real Diagnosis: Stack Assembly Fatigue, Not a Talent Gap
The instinct when AI projects stall is to hire. More ML engineers, more data scientists, more platform specialists. BCG's 2025 research on closing the AI impact gap frames it differently: enterprise AI success depends on prioritization, clear outcomes, and execution discipline, not raw headcount.
Hiring doesn't fix fragmented systems. It adds more people to a broken assembly line.
Here's the difference between the two diagnoses:
Talent narrative | Stack assembly narrative |
|---|---|
"We need more AI engineers" | "We're rebuilding the same five layers every sprint" |
"Our models aren't good enough" | "Our data isn't AI-ready" |
"We need a bigger team to ship faster" | "We need fewer handoffs between data, infra, and app teams" |
"Hire specialists for each layer" | "Collapse the layers into one governed system" |
The teams moving fastest in 2026 aren't the ones with the most AI headcount. They're the ones who stopped treating each feature as a greenfield infrastructure project.
How DataGOL Removes the Assembly Work
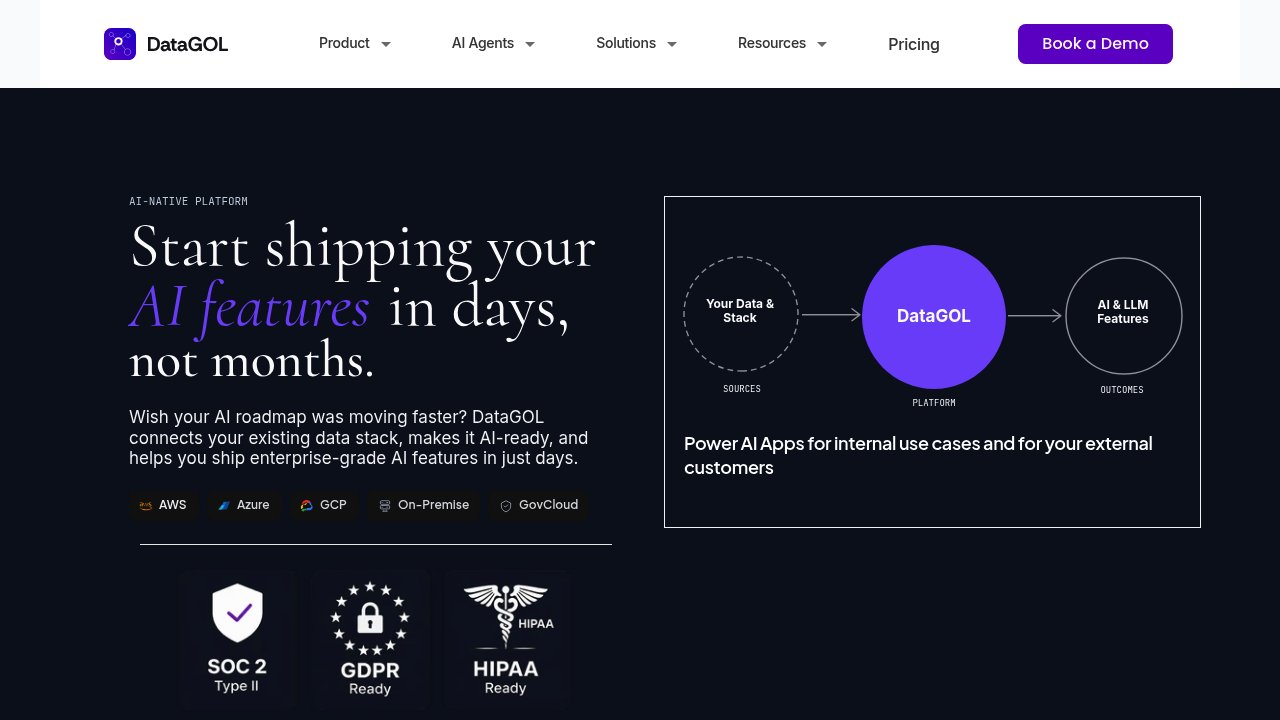
DataGOL is built as the layer underneath governed AI agents. It connects your existing data stack across 100+ pre-built connectors, makes that data AI-ready, and provides the context, orchestration, and agent harness work as a unified governed system, not a collection of tools you wire together yourself.
Beyond the data layer, DataGOL's AgentOS lets teams build and deploy agentic applications directly on top of that foundation. Each agent gets a defined role, strict authority levels, and shared context across the system. Governed execution means every action is routed through policy controls, approvals where required, and immutable audit logs. Teams can deploy pre-built agents out of the box or compose custom agents aligned to specific business functions, without rebuilding the underlying data and governance layer each time.
Here's what that looks like in practice:
Data connectivity (manual today): Writing and maintaining ETL pipelines per source. In DataGOL: 100+ connectors ingest, clean, and enrich data from your existing stack automatically.
Trusted context (manual today): Building custom retrieval layers and prompt context per feature. In DataGOL: Reusable business context is structured and governed once, then available to every agent via a shared context and memory layer.
Governed tool access (manual today): Negotiating security reviews for each new integration. In DataGOL: Permission controls, scope limits, and conflict resolution are built into the execution layer, not bolted on after.
Orchestration (manual today): Custom state machines and fragile multi-step agent logic. In DataGOL: AgentOS handles multi-agent coordination in the platform, not in your codebase.
Agent harness (manual today): Building eval, observability, and retry logic per agent. In DataGOL: Production-grade scaffolding, audit trails, and policy guardrails ship with the platform.
The result is fewer cross-team handoffs and a shorter path from pilot to production. DataGOL's own positioning puts it directly: "connects your existing data stack and makes it AI-ready."
Where DataGOL Fits Versus the Alternatives
Most teams evaluating this space look at three categories of tools. None of them solve the full problem on their own:
Tool category | What it does well | What it assumes |
|---|---|---|
Agent builders and frameworks | Orchestration, workflow design, LLM routing | Your data layer is already sorted |
Data platforms and warehouses | Storage, transformation, analytics | Someone else handles the AI execution layer |
DataGOL | Data connectivity + context + governance + orchestration + agent harness | Nothing. It's the assembled layer. |
Agent builders assume the data problem is solved. Data platforms assume the agent problem is someone else's job. DataGOL is purpose-built for teams where neither assumption holds, which is most teams actively shipping AI features right now.
Stop Rebuilding the Foundation
If every AI feature your team ships requires reassembling data pipelines, context layers, governance controls, and agent scaffolding, your velocity ceiling isn't the model. It's the foundation.
The teams shipping governed AI features in days rather than months aren't doing heroics. They're not running bigger sprints or hiring faster. They've removed the assembly work that was capping their speed in the first place.
If you're actively trying to ship AI features and keep hitting the same cross-team coordination wall, book a demo and see what the shorter path looks like in practice.


Author
Vinod SP
Seasoned Data and Product leader with over 20 years of experience in launching and scaling global products for enterprises and SaaS start-ups. With a strong focus on Data Intelligence and Customer Experience platforms, driving innovation and growth in complex, high-impact environments


