AI Feature Development Platforms: Missing Layer

The Missing Layer Between Your Data and Your Roadmap
Your AI roadmap is solid on paper. The use cases are documented in Jira, the model vendors are shortlisted, and the executive deck has a compelling vision slide. But execution is stalling and adoption is nowhere close to what was promised.
The data plane is fragmented across a dozen systems. The control plane does not exist. The execution plane is a proof-of-concept that impressed in the demo room and never made it to a single user.
This is not an unusual story. It is the dominant one.
According to RAND Corporation's 2025 analysis, 80.3% of AI projects fail to deliver their intended business value. Of those failures, 33.8% are abandoned before reaching production. MIT's Project NANDA study from July 2025 found that 95% of organizations deploying generative AI saw zero measurable return. Not low return. Zero.
The failure is almost never the model. It is the infrastructure surrounding it: the data that feeds it, the platform that hosts it, and the roadmap decisions that preceded it.
This guide covers three interconnected topics that SaaS product and engineering teams need to understand together, not in isolation:
What AI feature development platforms actually do and what separates the ones that accelerate shipping from the ones that create new bottlenecks
What data preparation for AI really requires and why "clean" data for reporting is not the same as AI-ready data
Why AI roadmaps stall and the specific, fixable causes behind most delays
If your team is building AI features and feeling the gap between ambition and production, this guide is written for you.
What Is an AI Feature Development Platform?
An AI feature development platform is not just a model API wrapper or a data warehouse add-on. It is a production-grade infrastructure layer that connects enterprise data, business context, retrieval, agent memory, governance, evaluation, tool execution, and embedded delivery into one coherent system.
Most teams underestimate how many layers sit between "we have data" and "we have a working AI feature in production." A build-it-yourself approach requires stitching together separate tools for each layer, each with its own failure modes, latency characteristics, and maintenance overhead. What looks like a model problem in production is almost always an infrastructure problem underneath.
The uncomfortable reality: most enterprise AI today operates with incomplete data, no organizational memory, and no real understanding of your business. It sounds authoritative. It responds instantly. And it is quietly wrong in ways that only surface after users stop trusting it.
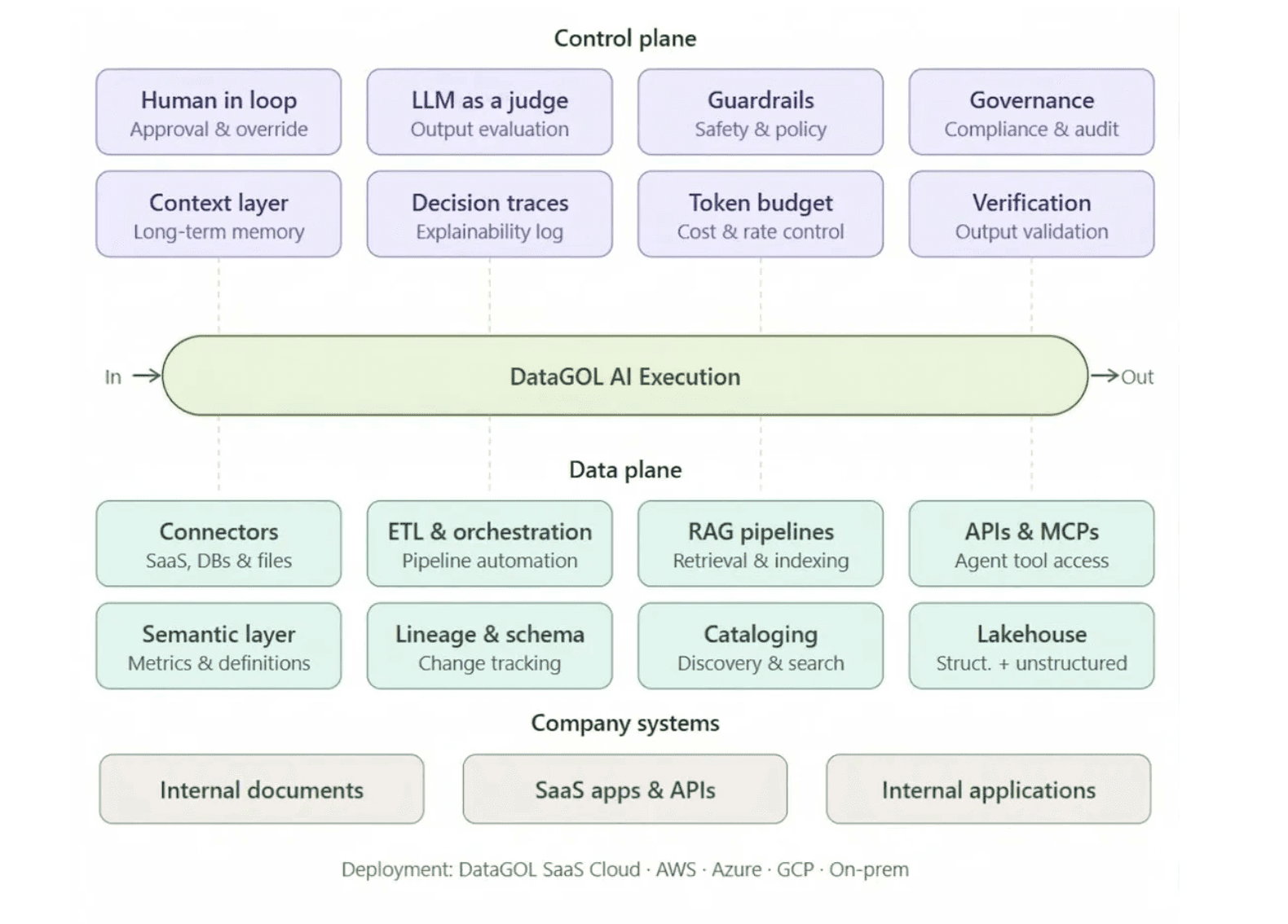
The Three Planes of a Production AI Platform
Production-grade AI feature platforms unify three distinct infrastructure layers. Understanding these planes is the clearest way to evaluate whether a platform is built for demos or built for real deployment.
1. The Data Plane handles how business data is made available and usable for AI. This includes:
Connectors to structured and unstructured sources (SaaS apps, databases, APIs, documents, event streams)
ETL orchestration and pipeline automation
A semantic layer that encodes metric definitions, entity relationships, and business logic so AI understands what the data actually means, not just what it contains
Lineage, schema change tracking, and a data lakehouse for durable, governed storage
Without a solid data plane, AI outputs are shallow, stale, or disconnected from real business operations.
2. The Control Plane governs quality, safety, and accountability across every AI action. This includes:
Guardrails and policy-aware execution to prevent unsafe or out-of-scope actions
Human-in-the-loop approval checkpoints for high-stakes decisions
Token budget management and abuse prevention (agent API keys must be distinct from user API keys)
Evaluation infrastructure: agent evals, workflow evals, regression testing, and model comparison to catch degradation before it reaches users
Audit logs, compliance workflows, and role-based access controls
Without a control plane, AI becomes too risky to deploy in real workflows, regardless of how well the model performs in testing.
3. The Execution Plane determines what agents can actually do and how reliably they do it. This includes:
Agent memory frameworks that persist user preferences, organizational context, and outcomes from prior tasks. Memory is not chat history. It is the evolving working memory of an intelligent system that gets smarter over time.
Advanced retrieval infrastructure that goes beyond basic vector search: graph relationships, structured queries, entity-aware joins, freshness handling, and business-context prioritization
Scalable MCP and tool interface infrastructure for APIs, internal services, SaaS actions, and workflows, with discovery, versioning, permissions, and policy enforcement built in
Long-running execution support for multi-step research, background tasks, asynchronous approvals, and workflows that span hours or days
Without a capable execution plane, AI agents remain glorified chat interfaces rather than durable systems that automate real work.
What Makes a Platform Production-Grade
Use this table as an evaluation framework when assessing platforms. Each row maps a production infrastructure requirement to what breaks when it is missing.
Production pillar | What it provides | What breaks without it |
|---|---|---|
Unified data foundation | Access to structured, unstructured, and event-driven business data | AI outputs are shallow, stale, or disconnected from operations |
Native context and semantic layer | Encodes metric definitions, entity relationships, lineage, and business meaning | Models retrieve data but misunderstand what it means |
Agent memory | Persists preferences, outcomes, and organizational context across sessions | Agents reset every session and cannot improve over time |
Advanced retrieval | Combines vector search, graph, structured query, and freshness controls | Responses are generic and miss business-critical nuance |
Traceability | Logs what data, model, tools, and reasoning path drove each output | Teams cannot debug, govern, or safely improve AI behavior |
Guardrails and governed actions | Applies permissions, approvals, policies, and audit trails before actions execute | AI is too risky to trust in real workflows |
MCP and tool execution | Lets agents call APIs, services, and workflows with discovery and policy controls | Tool use becomes a brittle integration surface and context bloat |
Evaluation infrastructure | Tests model, agent, and workflow quality continuously across releases | Upgrades silently break existing behavior with no early warning |
Shared foundation | One infrastructure layer for analytics, internal agents, and customer-facing AI | Three duplicate stacks with duplicate data movement, governance, and engineering effort |
The real cost of the wrong platform is not the license fee. It is the 12 to 18 months of engineering time rebuilding what a better platform would have provided on day one.
Gartner's research consistently shows that only 28% of AI infrastructure projects fully succeed and meet ROI expectations. Platform selection is one of the highest-leverage decisions a team makes early in the AI development cycle, and most teams treat it as a procurement decision rather than an architectural one. It is not. It is the foundation every AI feature you ship will be built on.
Data Preparation for AI: Why "Clean" Is Not Enough
Ask most data teams whether their data is clean and they will say yes. Ask whether it is AI-ready and the answer changes quickly.
Data that passes quality checks for BI dashboards and reporting can still be completely unsuitable for AI feature development. The requirements are fundamentally different, and teams that do not understand this distinction spend months cleaning data that still does not work in production.
Key distinction: Clean data for reporting means accurate aggregations and consistent field formats. AI-ready data means labeled inputs, rich metadata, versioned pipelines, and governance controls that allow a model to consume and trust the data at inference time.
The Five Requirements of AI-Ready Data
Gartner's February 2025 research found that 63% of organizations either lack or are unsure whether they have AI-ready data management practices. That gap is not a technology problem. It is a definition problem: teams are measuring data quality against the wrong standard.
Here is what AI-ready data actually requires:
1. Use-case alignment. Every data asset needs to be mapped to a specific business objective before any build starts. Broad data lakes with no use-case anchor generate high storage costs and near-zero production relevance. The audit should be scoped to the model's specific input requirements, not a general inventory.
2. Governance that is enforced. Asset-level ownership, access controls, and quality standards must exist in the pipeline itself, not just in a policy document. Governance that lives only in documentation does not protect models in production.
3. Active metadata management. Metadata needs to be machine-readable and continuously updated so AI systems can locate and trust what they consume. Static data catalogs go stale within 60 to 90 days. When models query data they cannot interpret reliably, outputs degrade silently.
4. Pipeline reliability with SLA guarantees. Pipelines that work in dev and fail silently under production load are one of the most common causes of AI feature rollbacks. Automated monitoring, SLA-backed freshness guarantees, and quality gates at each stage are non-negotiable.
5. Continuous quality assurance. A one-time data cleanup before launch is not a quality strategy. Ongoing anomaly detection, schema drift monitoring, and feedback loops back to source systems are required to maintain model performance after go-live.
The Hidden Cost of Skipping Data Preparation
Gartner predicts that 60% of AI projects lacking AI-ready data will be abandoned through 2026. That rate is already materializing: S&P Global Market Intelligence data from 2025 shows that 42% of U.S. companies have abandoned most of their AI initiatives, up from 17% the prior year. Of AI proofs of concept that were started, 46% were scrapped before reaching production.
The pattern is consistent: teams invest in model selection and infrastructure, then discover mid-build that their data cannot support what the model needs. The remediation cost at that stage is dramatically higher than it would have been if data readiness had been assessed before sprint one.
What AI-Ready Data Preparation Looks Like in Practice
For SaaS teams building AI features, the practical workflow looks like this:
Define the use case first, then audit data against it. Not the reverse.
Run a data readiness score for each input dataset: completeness, freshness, consistency, and governance coverage.
Build pipelines with production SLAs from the start, not as a retrofit after dev testing.
Establish schema drift monitoring before launch, so model degradation is caught automatically rather than by user complaints.
Version your training data the same way you version code. Reproducibility is a production requirement, not a nice-to-have.
The single most expensive mistake in AI feature development is treating data preparation as a pre-project task rather than an ongoing engineering discipline. Teams that get this right ship AI features faster and maintain them at lower cost. Teams that get it wrong cycle through repeated cleanup sprints that consume roadmap capacity for months.
For SaaS companies managing data from multiple sources, such as CRM events, product telemetry, payment data, and operational systems, the challenge is compounded by fragmentation. A platform that unifies ingestion and applies semantic modeling across those sources eliminates the most time-consuming part of data preparation before the AI development cycle even begins.
Why AI Roadmaps Stall: The Real Causes Behind the Delays
Most AI roadmap delays are diagnosed as resource problems or technical complexity. The actual causes run deeper and are more specific. Understanding them is the first step to building a roadmap that executes instead of perpetually slipping.
According to IDC research, 88% of AI proofs of concept never reach production. For every 33 AI pilots a company launches, only 4 make it to production. These pilots are not canceled. They are not progressed. They exist in a permanently provisional state that consumes budget and erodes executive confidence, a state practitioners have started calling "AI pilot purgatory."
Here are the six causes behind most AI roadmap delays, in order of how frequently they appear.
1. Data Unreadiness Discovered Mid-Build
This is the most common delay cause and the most preventable. Teams begin sprint planning before running a data readiness assessment scoped to the specific use case. When the model's input requirements collide with the actual state of the data, the project stops while data engineering scrambles.
What it costs: The average enterprise wastes 18 to 24 months on failed AI pilots, with costs ranging from $500,000 to over $3 million per initiative when accounting for technology investments, consulting fees, and opportunity costs.
The fix: Gate sprint one on a data readiness score, not a model selection decision. Data architecture should be validated before a single model is trained.
2. Roadmaps Built on Assumptions That Expire
AI benchmarks flip every three months. Model costs drop dramatically year over year. Open-source releases now routinely match or beat proprietary tools that companies budgeted for at the start of their planning cycle.
One documented case: a European enterprise scrapped a 2.4 million euro AI roadmap finalized just eight months earlier because the assumptions it was built on had already expired. The models they planned to use were no longer competitive. The infrastructure costs they budgeted were wildly overstated. The capabilities they thought would require custom development were available as API calls.
What it costs: Teams allocate engineering capacity to building what a commodity API now provides, while competitors who moved faster are already iterating on user feedback.
The fix: Build roadmaps in 90-day execution blocks, not 12-month plans. Treat AI roadmaps like product roadmaps: directional at the annual level, specific at the quarterly level, and revisable every cycle.
3. Platform Lock-In from Early Convenience Choices
Teams choose platforms that accelerate pilots but restrict future choices. Over time, data formats, tooling, and workflows become tightly coupled to a vendor's proprietary architecture. When the platform cannot support the next generation of features, migration costs are prohibitive.
The warning signs of lock-in risk:
Proprietary data structures that limit portability to other tools
Tooling dependencies embedded deep into core workflows
Limited transparency into cost and performance drivers as usage scales
No clear path to agentic or multi-model architectures
The fix: Evaluate platforms not just on what they can do today, but on whether they support open standards, portable data formats, and extensible architectures. A platform that costs 10x less in year one but requires a full rebuild in year two is not a bargain.
4. Misaligned Success Metrics
Projects survive 12 months with no clear answer to whether they are working. Activity metrics (model calls, feature impressions, usage sessions) replace outcome metrics (revenue impact, churn reduction, cost savings). The project looks healthy on a dashboard while delivering no business value.
McKinsey's 2026 Global AI Survey puts the ROI failure rate at 73%. A significant portion of that failure is not technical. It is definitional: teams never agreed on what success looks like before the build started.
The fix: Define a KPI ladder before sprint one. Lead metrics (early signals of adoption and usage) and lag metrics (P&L impact targets at 90 and 180 days) need to be documented and agreed upon before development begins.
5. Organizational Inertia and the Perpetual Visioning State
More time for planning does not produce better AI outcomes. It produces more reasons to delay. Stakeholders find objections. Governance reviews multiply. The perfect becomes the enemy of the good.
Gartner data shows that 45% of leaders in organizations with high AI maturity report their AI initiatives remain in production for three years or more, compared to only 20% in low-maturity organizations. The organizations that started executing early built operational experience that late movers cannot quickly replicate.
What it costs: Every month of delay means new features get built without AI in mind. Data pipelines get architected without consideration for AI training needs. Technical choices that would be trivial to change early become expensive migration projects later.
The fix: Treat AI execution like product development: ship a narrow version, gather feedback, iterate. The first AI feature does not need to be the definitive one. It needs to be in production.
6. Budget Concentrated on Technology, Not Process
Organizations allocate approximately 93% of their AI budget toward acquiring the technology itself, leaving 7% for the people and process restructuring required for success. This is why teams with excellent model access and modern infrastructure still fail to ship.
AI features require workflow changes, user adoption planning, and cross-functional alignment. None of those are solved by a better model or a faster GPU.
The fix: Rebalance the AI budget allocation. Technology is the enabler; process change is the delivery mechanism. Teams that invest in both ship faster and sustain longer.
The pattern across all six causes is the same: organizations are failing not because AI technology does not work, but because the conditions required for AI to work were never established before the build started.
How to Ship AI Features in Days, Not Months
The three topics in this guide are not independent problems. They are the same problem viewed from different angles.
AI roadmaps stall because data is not AI-ready. Data is not AI-ready because teams lack a platform that handles preparation as a native function. And platforms fail teams when they are selected for pilot convenience rather than production architecture.
Solving all three requires a platform that treats data readiness, AI feature development, and deployment as a unified workflow, not a sequence of handoffs between separate tools.
The Unified Platform Approach
The most effective AI feature development teams have moved away from assembling point solutions and toward platforms that collapse the full stack into a single system. The key architectural shift is treating data ingestion, transformation, governance, and AI inference as one continuous pipeline rather than four separate engineering efforts.
This approach delivers measurable advantages:
Faster time to production. When data preparation and AI development happen on the same platform, teams eliminate the integration overhead between layers. SaaS teams that previously spent 6 to 12 months on data infrastructure before writing a single line of AI logic can compress that to weeks.
Lower total cost. Fragmented tool stacks carry hidden costs: licensing for each point solution, engineering time to maintain integrations, and the organizational cost of context-switching between systems. A unified platform eliminates most of that overhead.
Better model performance. AI models perform better when they consume data that was prepared on the same platform that runs inference. Semantic context, metadata, and governance controls flow through the system without translation loss.
Reduced lock-in risk. Platforms built on open lakehouse architecture with standard connectors preserve optionality. Teams can adopt new models, add data sources, and extend to agentic workflows without rebuilding the foundation.
What This Looks Like for SaaS Teams
For a SaaS product team building an AI feature, a unified platform changes the development sequence fundamentally:
Connect data sources once. Pre-built connectors to Salesforce, Stripe, HubSpot, NetSuite, and 100+ other systems mean data is flowing in hours, not weeks.
Data is AI-ready from the start. The platform applies semantic modeling, governance controls, and quality monitoring as part of the ingestion process, not as a separate data engineering sprint.
Build AI features on verified context. Every agent or AI feature consumes the same governed, structured data. There is no "dev data" versus "production data" divergence.
Embed AI output directly into the product. Embedded analytics and AI delivery means the feature surfaces inside the product UI without a separate frontend integration effort.
Monitor and iterate. Schema drift detection, pipeline health monitoring, and feedback loops are built in, so model performance is maintained after launch without manual intervention.
The result is AI features shipping in days rather than months, at a fraction of the cost of a fragmented stack. For SaaS teams competing in markets where AI capability is now a product differentiator, the speed advantage compounds. Every week a competitor is in production gathering user feedback is a week of learning that cannot be replicated by a better roadmap document.
Key Takeaways
80.3% of AI projects fail to deliver intended business value. The cause is almost never the model.
AI-ready data requires use-case alignment, active metadata management, SLA-backed pipelines, and continuous quality assurance. Reporting-clean data is not sufficient.
Six causes drive most AI roadmap delays: data unreadiness, expiring assumptions, platform lock-in, misaligned metrics, organizational inertia, and technology-heavy budget allocation.
A unified AI feature development platform eliminates the integration tax between data preparation and AI deployment, compressing timelines from months to days.
Platform selection is an architectural decision, not a procurement one. The right choice preserves optionality and supports agentic workflows as AI capabilities evolve.
The gap between AI ambition and AI production is real, but it is not inevitable. Teams that understand the actual causes of delay, invest in genuine data readiness, and select platforms built for production rather than pilots close that gap faster than any roadmap revision will.
Explore the DataGOL platform to see how SaaS teams are shipping enterprise-grade AI features in days, with 90% less infrastructure complexity and at a fraction of the cost of alternatives.

DataGOL Revolutionizes Retail Operations for FreshMenu
Problem
FreshMenu faced opportunities to scale efficiently by addressing fragmented data sources, lack of real-time operational visibility, and limited customer data for personalization.

Author
Vinod SP
Seasoned Data and Product leader with over 20 years of experience in launching and scaling global products for enterprises and SaaS start-ups. With a strong focus on Data Intelligence and Customer Experience platforms, driving innovation and growth in complex, high-impact environments


